原文連結: Bridgewater’s AIA Labs Chief Scientist Jas Sekhon: AI Today and Tomorrow
AI 發展的現狀矛盾
我將討論當前 AI 的發展狀況,並提供一個框架,希望能幫助大家理解 AI 在不久的將來將走向何方。我也希望這個框架能夠幫助解決目前存在的一個矛盾,因為現在有兩件事情同時在發生。
一方面,某些資本配置者對 AI 在過去 12 個月的發展有些失望。像是 Sequoia 和高盛等機構正在質疑:「所有這些資本支出的需求在哪裡?目前 AI 產品在市場上並沒有產生太大的應用或興趣。」
但與此同時,在科學界,AI 的發展卻超乎預期,甚至在 AI 領域內部,本來就已經抱持著極高的期待。這並不只是計算機科學或 AI 專家自吹自擂,而是來自氣候科學、結構化學等多樣化的科學領域——許多 24 個月前仍被認為是科幻小說的問題,如今已經被 AI 解決了。
這兩件事是如何同時發生的?我希望能夠解釋這個現象。
要理解 AI 的未來與當前狀況,回顧其近期發展歷史是有幫助的。在這張圖表中,你可以看到 AI 的發展歷史,以及 AI 領域兩種不同學派之間的拉鋸——即所謂的「陰陽調和」。橙色代表的是「連結主義方法」(Connectionist Methods),它基本上是基於「歸納法」(Induction)。藍色則代表「符號主義方法」(Symbolic Methods),其基礎是「演繹法」(Deduction)。
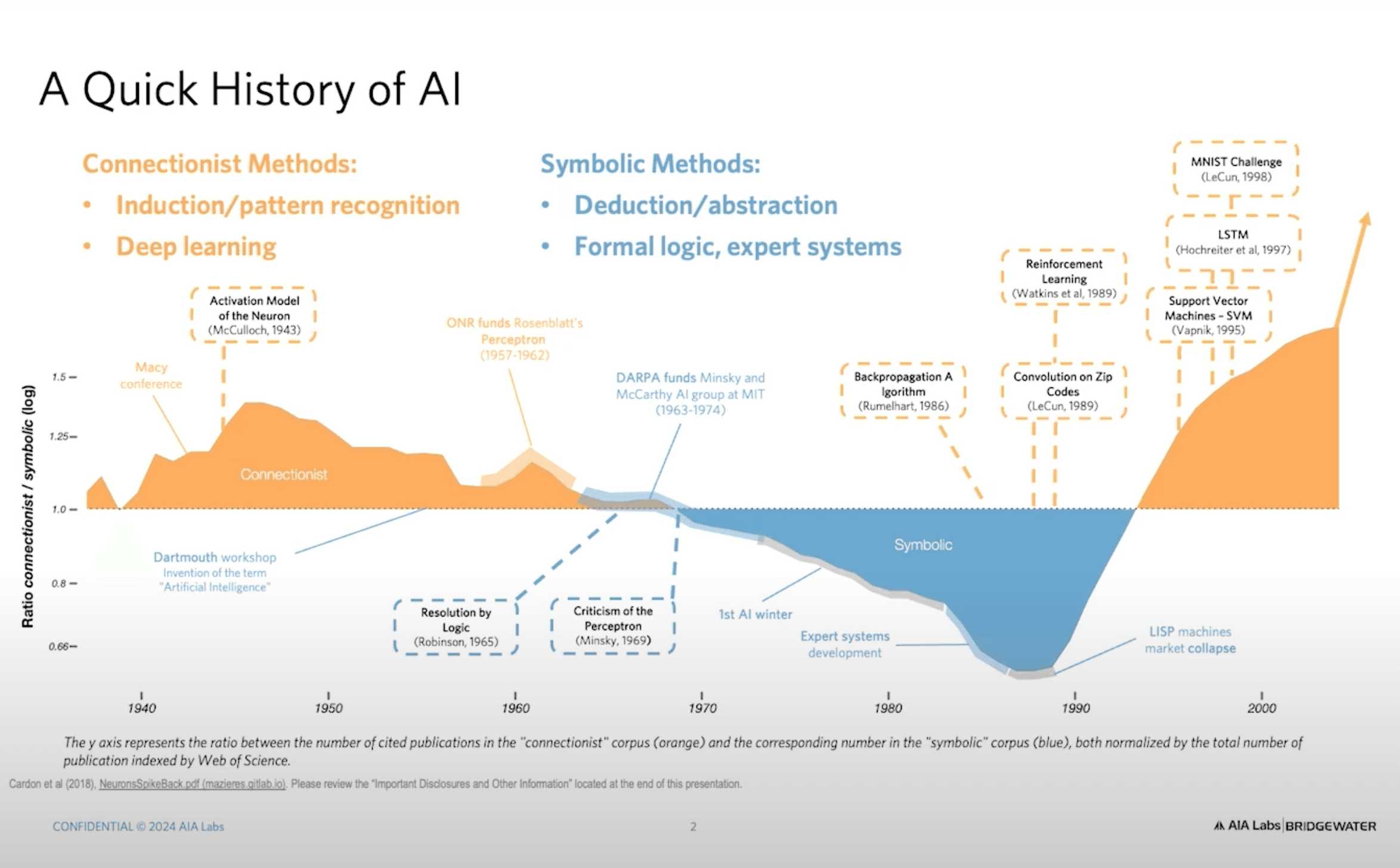
在這張圖表的 Y 軸,你可以看到科學論文發表比例的對數尺度,顯示出這兩種方法的興衰。除了某個短暫時期由符號主義方法主導,整體上 AI 領域長期以來都由連結主義方法所支配。事實上,你所聽過的所有關於 AI 進展的故事,基本上都是連結主義方法的成果。
那麼,什麼是連結主義方法?它基於一個非常簡單的概念:給我數據,不管是什麼類型的數據——可能是一堆文字、一張圖像的像素,或者是宏觀經濟統計數據——然後告訴我你想要預測什麼。你可以選擇預測下一個詞、下一次的經濟數據,或是一張圖片裡的物件(是貓還是狗)。在這個過程中,演算法會自行運作,這可能是一個難以解釋的黑盒子,但它會給出一個預測。只要提供更多的運算能力與數據,它就會變得越來越準確。如果這個過程持續進行下去,就能達到「智慧」。這就是連結主義的基本假設。
相比之下,符號主義方法認為,世界上不只有歸納法,還有演繹法。因此,這一派學者認為應該建立正式的邏輯系統,然後透過這些系統進行推理。最典型的例子就是計算機的計算功能——你的計算機無法在數學運算上出錯,因為它知道基本算術的規則。這些規則不是它自己學來的,而是人類事先寫下來並提供給它的。只要硬體沒有故障,它就不會犯錯。
另一個典型的符號系統是專家系統(Expert System),這也是一種符號主義方法的應用。然而,在現代 AI 領域,主流仍然是基於連結主義的深度學習(Deep Learning)。現在幾乎所有的 AI 研究與應用都圍繞著深度學習展開。
但是,這種歸納法與演繹法之間的緊張關係仍然存在,這也導致了我前面提到的 AI 發展的矛盾現象。
AI 在專業領域的突破性進展
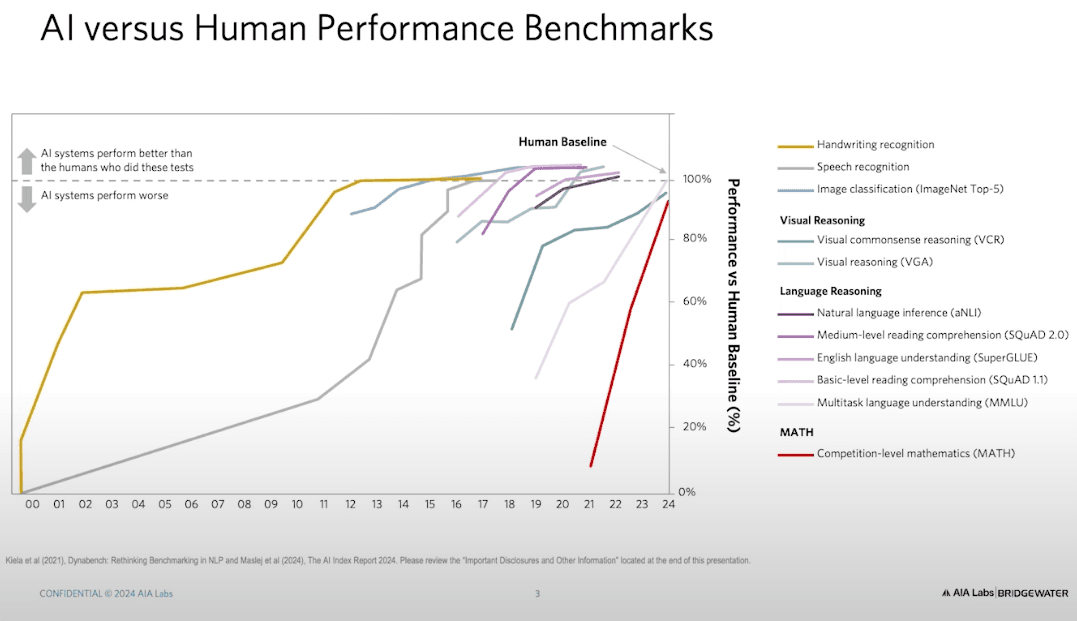
本世紀以來,連結主義方法的進展驚人。這張圖表顯示了本世紀以來各種 AI 基準測試的表現提升。圖中,虛線表示人類的表現水準。你可以看到,在 2000 年左右,當我剛開始從事科學研究時,一切都還算平穩。例如,當時的手寫識別技術才剛起步,大約 12 年後才達到與人類相當的水準(這對於美國郵政系統來說影響深遠,但對其他人來說影響不大)。
接著,語音識別技術的發展花費了更長的時間。但隨著 AI 進展加速,一切開始發生劇變。當時,斯坦福大學的 Fei-Fei Li 團隊發佈了一個圖像分類的基準測試,要求 AI 判斷一張圖片是貓還是狗。他們原本預測需要幾十年才能達到人類水準,但 AI 只用了幾年就超越了人類。
隨後,我們有了影像推理(Image Reasoning),然後是語言理解(Language Understanding)和語言推理(Language Reasoning),這些技術的進步速度遠超過人類的預期。
圖表中紅色標示的是數學(Math),這點特別值得討論。這裡的數學基準測試主要來自競賽級別的數學題目,適用於國中與高一程度的學生。這些題目超越了基本算術,涵蓋代數與幾何。在 2001 年,AI 在這個測試中的表現僅為人類水準的 6%。當時負責這個基準測試的研究人員(包括我在柏克萊的前同事)得出了一個令人沮喪的結論:「要在這個測試中表現良好,我們可能需要全新的科學突破。」
這是一個令人絕望的結論,因為「新科學」是無法預測時間的。你無法確定下一個冯·诺伊曼(Von Neumann)何時出現,也無法預測下一個愛因斯坦(Einstein)何時迎來他的「奇蹟年」(如 1905 年發表的一系列革命性論文)。新科學的誕生是不可控的,而科技與工程的發展則是可以掌控的。

然而,在今年初,我們在這個數學基準測試上的表現已超過 94% 的人類水準!當初被認為需要「新科學」的問題,如今 AI 竟然能夠解決。
你在這個基準測試中的表現已超過人類水準的 94%,而且所需的只是擴展規模——只要提供更多的計算資源與數據,並使用連結主義方法的常規工具。我們原本認為需要突破性進展的問題,其實並不需要。我稍後會再回到數學這個話題。
目前在文化上最受關注的是語言,而我認為這是因為我們早已習慣其他生物比我們跑得更快、力氣更大,但在這些語言模型出現之前,從來沒有任何東西能像我們一樣使用語言。我們曾以為這是我們獨有的能力,但現在機器也能做到,而且表現已超越人類水準。而且,這一切發生的速度極為驚人。
GPT-2 在 2019 年推出時,還像是在小學階段,甚至連數到 10 都做不到。如果你請它列出 10 個理由,它可能會給你 5 個,或是 15 個,內容荒謬不堪。要是它能完整寫出一句話,你就已經很滿意了。可是到了 2023 年,你會看到右側這些測試結果,顯示 AI 已在我們曾認為需要高度認知能力的測驗中表現超越人類。
我們有個傾向,一旦電腦能做到某件事,就會覺得這個測試不怎麼需要認知能力。但如果你回顧這些測試,我們當初都認為它們是需要高度認知能力的。例如第一個,我們談的是 AP 生物學測驗(Advanced Placement Biology)。這項測驗的成績達到 85% 百分位時,Bill Gates 才決定大舉投資生成式 AI。他原本以為這種表現至少需要一整代人的努力才能達成,結果 OpenAI 只花了六個月就做到了。
再來是法學院入學測驗(LSAT),這是為了大學畢業生申請法學院所設計的測驗。AI 在這項測驗中的表現達到了 88% 百分位,已經超過幾乎所有美國法學院的平均錄取分數。
最令人印象深刻的是神經外科專業考試(Neurosurgery Board Exam),這項測驗的題目並未出現在 AI 的訓練數據中。美國的神經外科是培訓時間最長的醫學專業,參加這項考試的人,已經完成了大學學業、醫學學位、住院醫師訓練,甚至是外科次專科的研究培訓,這是他們的最終考試。而 AI 在這項測驗中取得了 83% 的分數,在過去十年內,沒有任何人類考生的成績超過 90%。這個分數被認為是「高通過」(high pass)。
當這篇研究論文發表時,我正在與 Harvard 和 Yale 醫學院的院長們開會,他們的臉瞬間變得蒼白。他們說:「醫學界再也不會一樣了。」這項考試並不是單純的記憶測驗,而是測試鑑別診斷(differential diagnosis)和推理能力,而這原本被認為是極為困難的任務。
雖然 AI 在這些領域的進展驚人,但值得注意的是,至今幾乎所有機器學習帶來的經濟價值,都與生成式 AI 無關,而是來自於傳統的機器學習。它主要應用於預測,並且幾乎都由美國科技巨頭所掌控,這些公司打造了全球規模的機器學習系統。例如:
Amazon 使用機器學習來建立全球供應鏈系統,透過預測需求與供應曲線,來最佳化價格匹配。
Google 利用機器學習技術來投放廣告,以最大化精準度。
Facebook 也在做類似的事情,透過機器學習來最佳化廣告投放。
NVIDIA 則利用機器學習來設計下一代晶片。
為什麼這些科技巨頭能獨占這些價值呢?因為這些工具極其難以使用,需要大量資本與科學專業知識。而科學專業知識不僅難以獲取,還必須有效管理並運用到生產之中。
大型語言模型的現有限制

目前大型語言模型(LLMs)雖然吸引了最多關注,但它們仍然非常難以操作。目前的主要限制在於,它們難以逐步推理(step-by-step reasoning)。它們擁有大量的知識,因此從某種角度來說,它們非常聰明。例如,這些系統對熱力學定律(Laws of Thermodynamics)有深入理解,同時也了解《哈姆雷特》中的角色 Rosencrantz 和 Guildenstern。能同時掌握這兩類資訊的人類少之又少,而這些 AI 系統卻能做到。
所以從這個角度來說,它們確實非常聰明,但如果是需要逐步思考的邏輯難題,例如讓它們一步步推理並記住自己的過程,它們就會崩潰,表現非常糟糕。因此,目前如果要使用大型語言模型來幫助設計軟體,它們的角色就像是副駕駛(co-pilots),程式設計師可以在寫程式時利用它們,當開發人員開始輸入代碼時,AI 會提供建議來完成程式碼。這確實有一定的用處,但它如何影響經濟或某個特定公司,仍然取決於程式設計師是否願意使用它,或者是否會調整自己的程式設計方式來適應它。這是一個相當困難的問題。
目前,這些模型無法做到的事情之一,就是充當遠端員工。你無法像僱用一名位於西班牙或印度的遠端員工那樣,直接告訴它:「請修復這個 bug」、「請新增這個功能」或「請開發這款軟體」,因為它們無法長時間專注於任何特定的任務。因此,它們無法像業界所說的那樣具備「代理行為」(agentic behavior)。
大約 12 個月前,矽谷的共識是:「好吧,我們知道目前的狀況,但我們可以透過提供大量工具來解決這個問題。」然而,這些大型語言模型居然無法做數學,這是當初沒有人預料到的。但我們有計算機,我們可以提供程式設計工具以及其他各種工具,很快它們應該就能處理企業後台作業,例如編寫複雜的程式碼,甚至解決許多商業問題。
問題是,它們的注意力跨度極短,就像金魚一樣,甚至無法有效使用這些工具。如果要讓它們真正發揮工具的作用,就需要高度的科學專業知識,以及大量資本來解決問題。但問題是,誰擁有這樣的資源組合?如果你是 Google,當然能做到;如果你是某個科學研究實驗室,研究的是蛋白質折疊或尋找新型抗生素,那麼你也可以做到。但如果你是 Ford,或者是經濟體中的任何一般企業,那就不太可能,因為你沒有這樣的基礎設施。因此,除非企業獲得這類專業知識,否則要使用這項技術將會非常困難,或者,這項技術本身必須變得更容易使用。
AI 發展的兩條路徑

所有的基礎研究實驗室都知道這點:Google 知道、Anthropic 知道、OpenAI 知道、Meta 知道、Mistral 也知道。所以,他們的策略是:「我們要讓這些工具更容易使用。」目前有兩種主要的路線來實現這個目標。
第一種方式是「擴展規模」(scale)。這場 AI 革命的有趣之處在於,最簡單的方法往往最有效。最簡單的方法是什麼?就是提供更多數據和計算資源。這看起來好像很簡單,但實際操作起來並不容易。不過,這並不需要 Albert Einstein 來發明全新的算法,只要不斷增加數據和計算能力,就可以讓 AI 變得更強。例如,ChatGPT-2 甚至無法數到 10,而 ChatGPT-4 已經能夠完成許多高階推理任務。這並不是因為我們發明了新的算法,而只是因為我們給它提供了更多數據和計算資源。因此,這是一個可行的發展方向,我們會繼續擴展規模。
第二種方式則是採取更有創意的做法,即回到 AI 研究中被遺忘的「符號學派」(symbolic AI),並將「逐步推理」(step-by-step reasoning)內建到模型之中。這是一種試圖讓 AI 具備推理能力的方式。舉例來說,OpenAI 上週剛發布的一款新模型,採取的就是這種策略。它與之前的模型相比,計算資源並沒有增加,但內建了更多推理能力。因此,目前 AI 發展有兩種可能的未來方向。
第一種是樂觀的情境(bullish case),也就是所有研究機構和科學社群都在努力實現的目標,即讓大型語言模型具備「代理行為」,能夠自主規劃,即使它們的智慧水準沒有進一步提升也無所謂。畢竟,正如剛才所示,它們已經擁有超越人類的知識,如果再加上計畫與執行能力,那將創造巨大的經濟價值。這樣一來,企業就不需要重新組織架構,AI 可以像遠端團隊一樣運作,管理難度與現有的全球遠端團隊相當,無需額外招聘一大批博士或專家,技術便能自然融入現有的工作流程,並催生大量新產品。這是樂觀的未來,也是許多團隊正在努力實現的方向。
如果這個目標沒有實現,那麼就會進入較為悲觀但仍然具轉型性的情境(less bullish case)。這種情況下,AI 技術將需要長時間的演進,像歷史上的所有通用技術一樣,發展過程將會是一場漫長的「磨合期」(slow grind)。這就像當年電力的普及過程一樣。當電力剛出現時,工廠老闆認為:「好,我有電了,我應該用電動發電機取代我的蒸汽發電機。」結果生產力反而下降,因為蒸汽發電機的機械力更大,能夠提供更高的輸出。
結果導致所有機器運作不良,生產力甚至下降,這是一個負面的生產力衝擊。當時工廠老闆心想:「我花了這麼多錢,結果生產力不增反降?」後來,有人靈機一動,發現電動發電機與蒸汽發電機不同,電動發電機可以並聯安裝,甚至可以自由移動,不必集中在同一棟建築內,這樣一來,工廠的工作效率才真正提升。但這個轉變花了 25 年,因為土地利用方式要改變,工廠結構要改變,工人也要重新適應,一切都需要調整。這意味著,當人們從蒸汽轉向電力時,最初生產力是下降的,直到後來才迎來真正的生產力提升。而這個過程,涉及企業端的大規模資本投入與人力再訓練,這其實是幾乎所有技術創新的歷史規律。
如果我們無法解決 AI 的「代理行為」問題,這很可能會是 AI 發展的基本情境(base case)。但即使如此,這仍然是一個非常樂觀且快速的情境。
AI 在數學領域的驚人突破

如果回顧 AI 在數學領域的進展,2021 年的科學家還在擔憂:「我們需要新的科學突破,因為 AI 目前無法解數學題。」
但到了今年年初,當我們用 AI 參加最困難的數學競賽——國際數學奧林匹亞競賽(IMO)時,GPT-4 在該測試中得分 0%,連一道題目都答不對。但這也沒什麼,因為大多數普通人參加這類考試也得不到任何分數。然而,當時許多人認為,要讓 AI 具備這種能力,可能需要好幾個世代的努力。但 DeepMind 表示:「我們可以解決這個問題。」
結果,在短短一年內,AI 在 IMO 的幾何測試中獲得了 金牌級成績,正確率達 83%,而最新的模型甚至能在幾何部分達到 100% 正確率。這意味著,AI 現在能夠完美無誤地進行歐幾里得證明,而六個月前它的成績還是 0%。如今,AI 在 IMO 的整體測試(涵蓋代數、數論等領域)已達到 銀牌 水準。
這些考試的難度極高,如果一個普通人接受無限的訓練,即使花費 10 億美元 培訓,也幾乎不可能在國際數學奧林匹亞競賽中獲得金、銀或銅牌。這與讓普通人奪得奧運 100 公尺短跑金牌 的機率差不多。因此,AI 能夠達到這種水準,意義非凡。而現在的預測市場也顯示,到 明年,AI 很可能能夠在 IMO 競賽中獲得金牌。
但要做到這一點,仍然需要具備 Google DeepMind 級別的資本支出、大量博士級人才,並解決過去看似無法解決的問題。這就是為什麼 AI 科學界感到興奮。舉例來說,過去 50 年來最偉大的數學家之一 Terry Tao 看過這些 AI 模型後表示:「它們現在的數學水準,已經相當於一個平庸的數學研究生。」但來自 Terry Tao 這樣的人物的評價,實際上是極高的讚譽。畢竟,一年前 AI 在數學領域的表現還完全不行,現在卻已經達到這樣的水準。
你不一定需要像 Google 一樣龐大的資本投入,但仍然需要專業知識。另一個例子是,我們一直在與抗藥性細菌作戰,因為我們正在耗盡有效的抗生素。這本身是一個經濟問題,但總之,人類歷史上已知的所有化學分子只有 1 億種。
因此,加拿大 McMaster 大學 和 史丹佛大學 的一個團隊決定:「為什麼不讓 AI 來分析 300 億種 可能的分子?」這在人類歷史上是無法想像的,因為人類科學家不可能逐一檢查這麼多化學分子。但現在,他們讓 AI 來試試看,看看它是否能找到新抗生素。這與一般 AI 替代人類的應用不同,因為這項任務是人類本來就無法完成的。
結果,這個 AI 系統分析了 300 億 種分子,然後篩選出 56 種 可能有效的分子,最後送入實驗室測試,發現其中 6 種 真的可以殺死抗藥性細菌。這個 6/56 的成功率 遠高於人類藥物開發的成功率。而這一切,都發生在過去幾個月內。
這就是 AI 的「樂觀情境」:即使我們還沒有完全解決 AI 的計畫能力問題,它已經能夠帶來驚人的結果。但我們仍然希望讓這項技術變得更容易使用,因為我們的兩條發展路徑仍在進行:
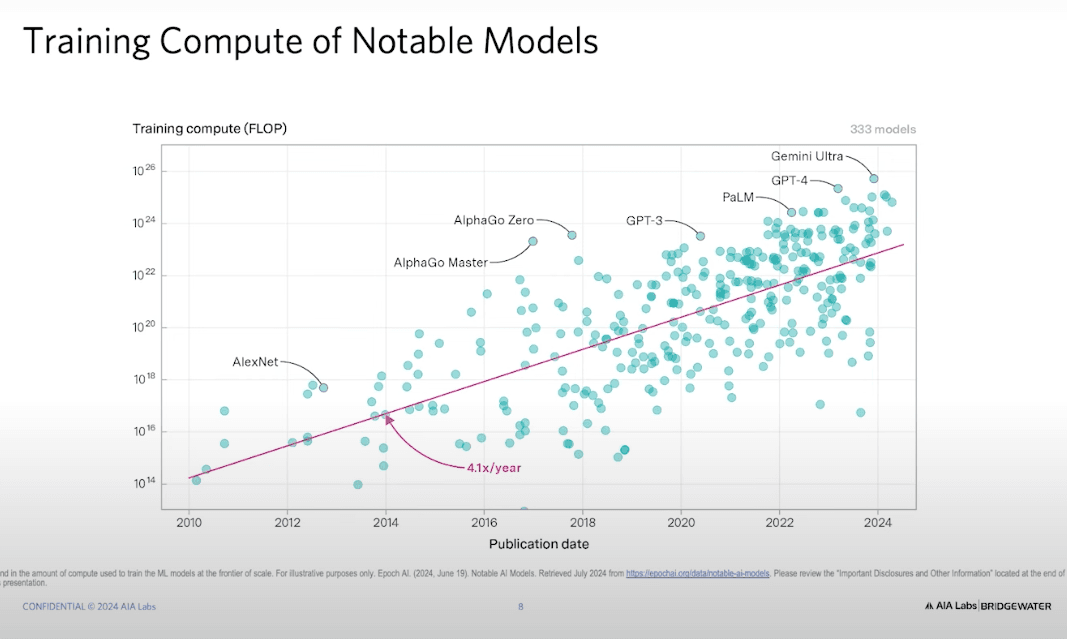
擴展規模(Scaling):過去幾年,提供給 AI 的計算能力 每年提升 4 倍,最近的增速甚至達到 5 倍,這意味著每兩年運算能力提升 10 倍(10x improvement)。這也帶來了資本支出的巨大增長。
改進算法(Improving the algorithms):除了提升硬體計算能力,研究人員也在致力於改進 AI 的推理能力,讓 AI 變得更智能。
這些發展正在快速推進,未來 AI 可能會以更加驚人的速度進化。
如果這樣來看的話,ChatGPT-4 是在 2022 年訓練 的,然後 2023 年發布。訓練它所需的 數據中心 建設成本高達 4 億美元。如果你 Google 這個數字,可能會看到 1 億美元,但那只是訓練成本,不包括數據中心的建設成本,真正的數據中心成本是 4 億美元。這聽起來很多,但現在我們已經在建造 百億美元級別的數據中心。
甚至有洩露的消息顯示,微軟與 OpenAI 合作的 「Project Stargate」 計畫,目標是建立 千億美元級別的數據中心。換句話說,這個擴展規模(scale)的趨勢還在持續進行。問題是,當我們的規模越來越大,效能是否還會繼續提升?目前的答案是:「我們不知道,直到我們嘗試看看」。但資本仍在投入,所以擴展規模的路線還在持續發展。
但不只是規模的提升在推動 AI 進步,演算法(algorithm)也在不斷進化。供應鏈的各個環節都在創新,而這些創新幾乎全部發生在美國,特別是 舊金山灣區(San Francisco Bay Area)。這個區域在 AI 領域的影響力甚至比歐洲和亞洲所有國家加起來還要大,但許多人沒有意識到這一點。如果歐洲和亞洲的 AI 創新完全消失,對全球 AI 進步的影響可能還比不上舊金山灣區的任何一個 AI 研究機構。
硬體與演算法的競賽
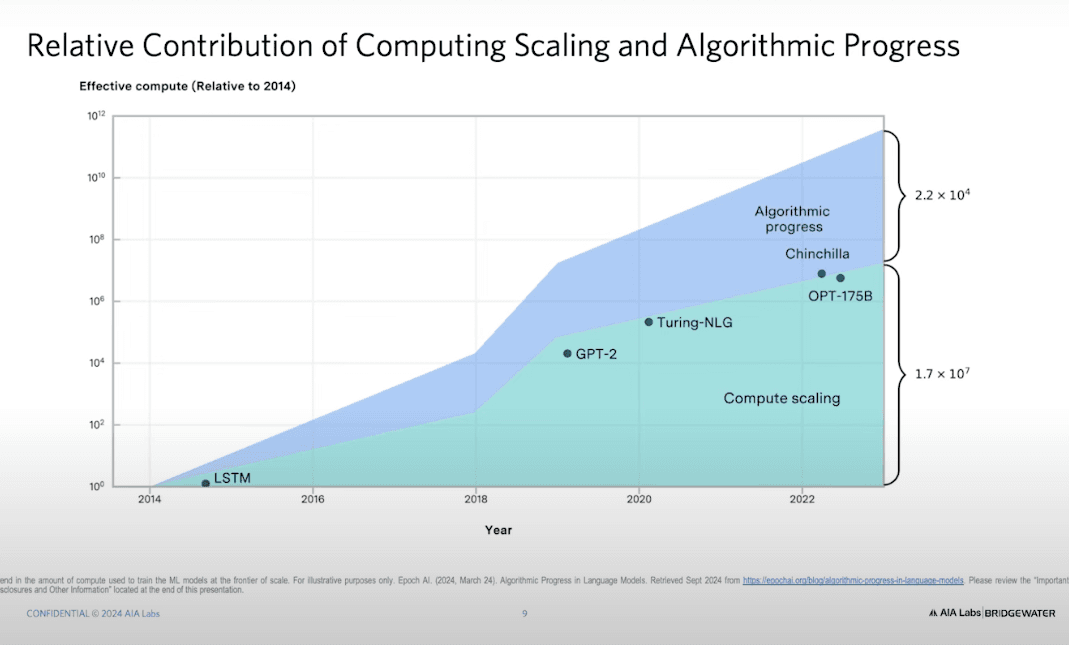
如果你觀察 AI 計算能力的增長曲線,你會發現 大部分增長還是來自硬體提升(例如 NVIDIA 提供的計算能力),但來自演算法的進步也在快速增加。這就像一條正在增長的「藍色區塊」,代表我們不只是單純透過更強大的硬體來提升 AI,我們也在發掘更優秀的演算法。
然而,最近這幾年,這方面的研究開始變得 非常安靜,不再公開發表研究論文。這並不是因為研究人員不再交流,而是企業開始將這些突破視為關鍵的智慧財產權(IP),政府也將其視為國家安全核心技術。
目前,AI 界最重要的進展來自演算法,而非單純的計算能力提升。但現在這些演算法研究基本上都被 封鎖 了,企業不願意公開,國家安全機構也要求**「請務必鎖住這些技術」**,因為這已經影響到國家安全與全球競爭力。
這意味著,AI 可能正在進入一個**「安靜的時期」**(silent period)。在這段期間,演算法的進步可能會繼續加速,但不會對外公開,因為這已經成為企業與政府共同關注的戰略資產。
主要 AI 實驗室的競爭 目前,領先的 AI 實驗室都將 AI 視為「潛在的生存風險」(existential risk),因此它們的投入金額已經超越了以往的標準,而且它們的技術發展速度正在快速收斂。
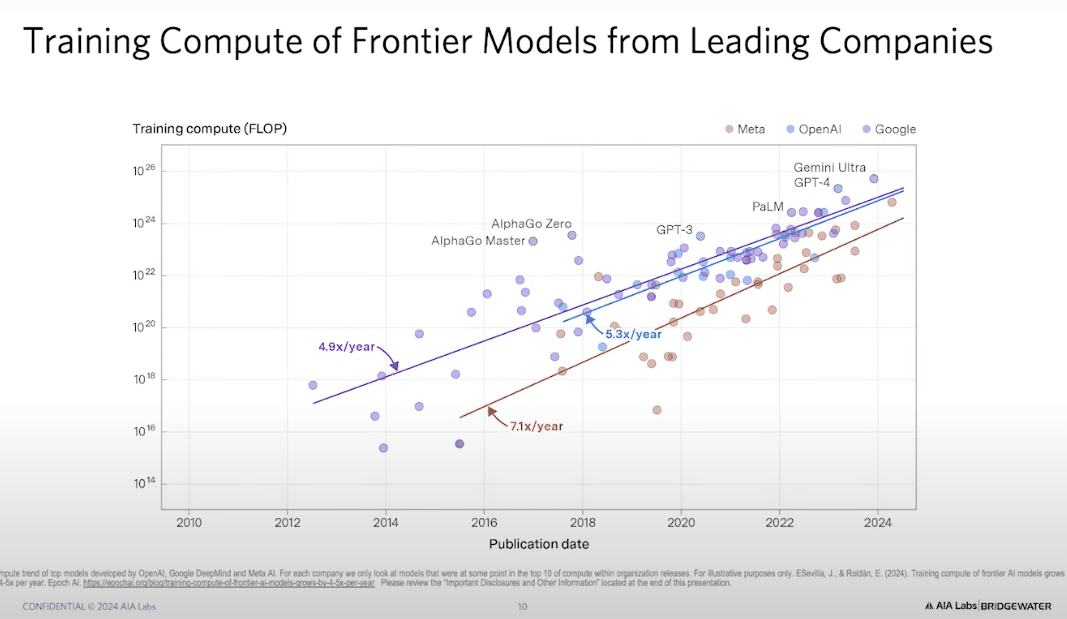
從數據來看(Anthropic 的數據缺失,但趨勢類似),OpenAI、Google DeepMind、Meta(Facebook)、Elon Musk 的 xAI 都在以 每年 5 倍~7 倍 的速度增長計算能力。而根據 AI 的「擴展定律」(Scaling Laws),當這些實驗室的計算能力收斂時,它們的模型效能也會趨於相近。
這就是為什麼現在 AI 競爭的模式變成**「不斷交替超越」**:
Claude(Anthropic) 曾一度超越 GPT-4。
Google Gemini 曾短暫領先,但很快被其他模型反超。
最新的 OpenAI 模型 在上週發布後,又成為目前最強的 AI。
這種「互相追趕與超越」的模式,將持續發生,直到計算能力與演算法的進步趨於穩定。
要預測誰會贏是非常困難的,因為最大的競爭者們認為這對他們來說是生存風險(existential risk),因此他們正在投入大量資本來實現這個目標。這其中很大一部分取決於計算資源的分配,因此很難預測誰最終會勝出。
不同的競爭者有不同的激勵機制。在科學應用領域,Google DeepMind 遙遙領先,這完全符合他們的研究熱情。他們是解決蛋白質折疊問題(protein folding problem)的團隊,並且選擇將這些研究結果無償分享給全世界,因為他們的目標是改變醫學領域,而不是透過蛋白質折疊的數據來盈利。然而,Google DeepMind 目前尚未為消費者或企業推出他們最先進的模型,而OpenAI 和 Anthropic 由於其業務結構的關係,需要提供這些最優秀的模型,因此它們的產品面向最終用戶。
結論:AI 的未來發展方向
總結來說,希望你能理解為什麼科學界對 AI 充滿興奮,即便是那些並非直接研究 AI 的科學家,因為他們擁有專業知識來掌控這些極難控制的模型。同時,商業界 仍然處於觀望狀態,因為許多企業尚不確定該如何使用這些技術,也不確定如何從中獲取價值。這主要是因為目前市場上缺乏足夠的專業人才來充分發揮這些技術的潛力。
但最終,企業將會逐漸適應這些技術。這個過程可能會緩慢發展,透過逐步培養更多專家,讓這些技術逐漸滲透到經濟體系中,就像電力的普及過程一樣。如果我們回顧十年後,會發現整個經濟已經發生了根本性的變革。
或者,這個轉變可能會非常迅速,如果AI 基礎研究實驗室(foundation labs) 和技術開發團隊能夠解決「規劃問題(planning problem)」。根據OpenAI 最新發布的模型的早期報告,這款模型在推理能力上明顯優於之前的版本,這代表它正朝著最樂觀的發展方向邁進,試圖解決這個問題。
但這條道路仍然漫長,目前仍難以預測哪一種模式會最終獲勝。